Getting closer to 'Her': From Moshi to Thinking Machines Interaction Model
a story of how an open source lab from France paved the way to this beautiful experience and Thinking Machines team took it to the next level. Also, how this give Cerebras a strong product market fit.


The new shape of intelligent experience
For last few years, every product team building on top of language models for voice experience has been forced to pick a corner of an awkward triangle: you could have fast, you could have smart or you could have cheap; but not all three at once. Real-time voice assistants were small and dumb because anything bigger could not respond inside a human’s patience window. Frontier reasoning models were astonishing in benchmark tables, but their real time voice versions felt lacking. If you found something that was intelligent and fast, it was also very expensive. In addition to experimenting with natively multimodal models, developers also tried cascading state of the art models together: ASR, LLM, TTS with each layer adding latency, each handoff losing context, each silence between turns reminding you that you were talking to a machine.
The interaction-model and background-model split, as proposed by Thinking Machines (TML), is the first credible answer to that triangle. By assigning the two halves of intelligence to different hardwares on different latency budgets, the architecture sidesteps the trade-off rather than negotiating with it. The half that has to be present is allowed to be small, fast, multimodal, and continuously attentive — five times a second, no exceptions. The half that has to be smart is free to be enormous, slow, deliberative, and tool-using, because it is never on the critical path of the 200ms cadence. Neither side is asked to compromise on what it is good at. The user experiences both, fused.
What does that unlock concretely? Consider the experiences that have been technically promised for a decade and have never quite worked:
A language tutor who can listen to you stumble through Spanish, gently correct your pronunciation mid-sentence, and simultaneously plan a six-month curriculum tailored to where you actually struggle. The interaction model handles the listening and the correcting in real time. The background model is somewhere else, watching your error patterns accumulate, deciding when to introduce subjunctive mood, drafting tomorrow’s lesson while you finish today’s.
A cooking companion that watches your hands through your phone camera, calls out that the onions are about to burn, and pulls up a substitute when you realise you’re out of cumin — without any of those interactions feeling like separate apps. The visual perception is handled in the 200ms loop. The recipe knowledge, the substitution reasoning, the meal-planning context lives in the background.
A therapy or coaching presence that can simply be there in long sessions, patient, responsive, never lagging; while the background model does the genuine work of remembering what was said three weeks ago, noticing a pattern across months, deciding when a gentle reframe is appropriate.
A workplace assistant that is actually in the meeting with you, not transcribing it for later. It can interject with the relevant figure when someone mis-cites a number, surface the Slack thread that supersedes a decision being re-debated, and do all of that without the awkward “OK assistant, are you there?” preamble that makes today’s tools feel like talking to a Roomba.
The pattern is the same in every case: the experience becomes natural when being there and being smart stop competing for the same compute budget. Once you stop forcing one model to do both, the entire UX problem dissolves. The model that’s there is allowed to be specialised for presence. The model that’s smart is allowed to be specialised for thought. They cooperate over a thin interface, and the user perceives a single attentive intelligence that, finally, does not punish them for talking the way humans talk.
This is what people mean when they say voice is the next interface. It was never really about voice. It was about whether intelligence could show up in the room without making you wait for it. The split architecture is the first proof that it can.
Finally we can have an ever present intelligent, responsive compassionate assistant like that showed in 2013 Science Fiction romance movie “Her”. This blog will discuss key technological milestones that led us to this point.
Welcome Thinking Machine’s Interaction Model
I have been mesmerised by the demos coming out of Thinking Machines interaction model. It is the same kind of mesmerisation I felt the first time I saw Kyutai’s Moshi, and then again when Sesame dropped (try the preview on their site — it is worth the click). We are getting closer to “Her”. Top tier intelligence, with high interactivity and compassion.
What is striking is that both Sesame and Thinking Machines’ new interaction model lean heavily on ideas pioneered by Kyutai’s Moshi. If you want to understand how Thinking Machines manages to combine frontier-grade intelligence with sub-second responsiveness, the most useful prerequisite is Moshi and its retrieval-augmented successor MoshiRAG.
The Thinking Machines (also referred to as TML) blog post is however sparse on how their interaction model interacts with their background model that does the asynchronous heavy lifting, and that is the gap this blog tries to fill.
I also call out differences between TML’s approach and that of Moshi’s on input side.
I also want to take a moment to thank Kyutai lab who build and open sourced Moshi and also to thank Thinking Machines team for taking the torch further and bringing us closer to “Her”. As discussed, the kind of applications it is going to enable are going to be profound. This one is one cool example:
Major milestones on the way
Most language models still treat conversation as a turn-based protocol: you finish, then I speak, then I finish, then you speak. That works for chat boxes. It falls apart the moment you want a model to translate live, count your push-ups, or stop you mid-sentence when you have made a factual error. Real conversation is full-duplex, because both parties produce and perceive at the same time, and silence and overlap carry as much information as the words.
Three lineages have been pushing at this problem from different angles. Moshi rebuilt the speech LM stack around a dual-channel architecture. Sesame scaled it to a level where it started feeling magical. MoshiRAG bolted on asynchronous retrieval to fix factuality without sacrificing real-time flow. And Thinking Machines’ interaction model takes both ideas and scales them to a 276B MoE backbone, to video, and to a deliberately tiny 200ms micro-turn cadence.
1. Moshi: the dual-channel foundation

Kyutai’s Moshi (2024) is a 7B parameter speech-text foundation model built on an RQ-Transformer (the paper). There are two transformers stacked together:
A “temporal” Transformer running at 12.5 Hz, processing one frame every 80ms.
A “depth” Transformer that, at each temporal step, predicts 8 audio codebook tokens — Moshi’s actual speech output, encoded by the Mimi neural codec.
The key trick is that Moshi is dual-channel: it ingests the user’s speech tokens and predicts its own speech tokens simultaneously, in interleaved streams. There is no voice-activity-detection harness deciding when it is “the model’s turn” — at every 80ms frame the model is free to speak, stay silent, backchannel, or interrupt. This is the architectural foundation that everyone in the modern full-duplex space, including Sesame builds on. Thinking Machines changes it a bit that we will see in detail.
2. Sesame: refining the experience

Sesame’s Conversational Speech Model takes the same full-duplex spirit and pushes hard on voice quality and emotional naturalness. The public technical details are slimmer than Moshi’s (which has an open paper), but the design lineage — continuous bidirectional audio streams, no separate VAD harness, low-latency codec output — is unmistakably Moshi-style. If you have tried the preview, the demo experience speaks for itself.
3. MoshiRAG: thinking while talking
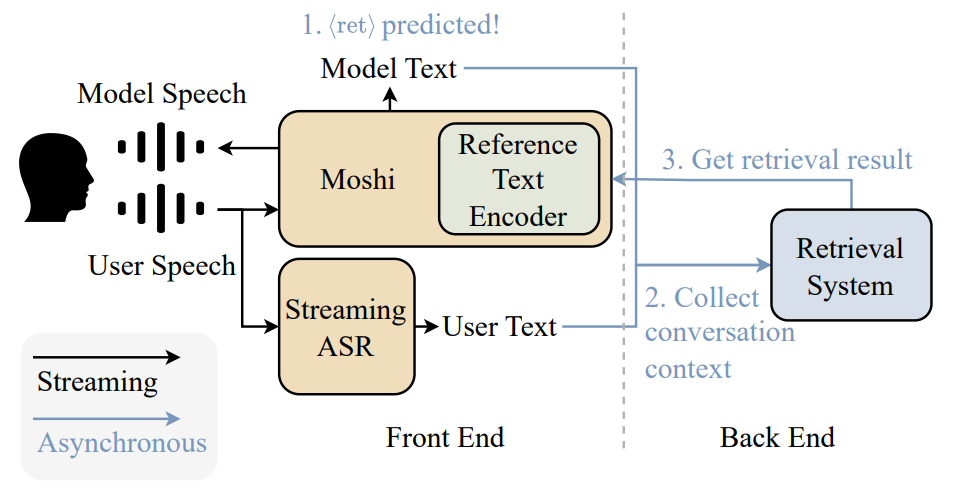
Moshi has one weakness that is hard to engineer around at 7B parameters: factuality & intelligence. Speech LMs are trained on vastly less text (in word count) than text-only LMs, and it shows on QA benchmarks. The obvious fix is to make the model bigger, but a bigger model cannot run in real time. Kyutai’s answer, published in MoshiRAG in April 2026 (the paper), is to split the system in two:
A front end that stays small and real-time (this is similar to TML’s interaction model) — Moshi 7B, a 1B streaming ASR, and a frozen reference text encoder (ARC-Encoder).
A back end that handles knowledge retrieval asynchronously (this is similar to use of a background model by TML) — a local LLM like Gemma 3 27B or an API call to GPT-4.1.
The two are connected by a single new token. When Moshi sees a knowledge-intensive question coming, it predicts a <ret> token in its text channel. That fires off a retrieval call. Crucially, Moshi does not wait for the answer — it keeps speaking, producing a “pre-RAG” lead like “Let me think about that...” or “In the Netflix series...” that buys the back end roughly two seconds of slack. By the time Moshi reaches the body of its answer, the retrieved reference is ready.
An ASR model transcribes the user speech and that with useful context is provided to the back end model to do its work.
How the retrieved answer gets back into the stream
This is the part most people get wrong on first reading. The retrieved reference is not injected as user text, nor as model text, nor as audio. It comes back as a sequence of continuous embeddings — produced by ARC-Encoder, compressed 4× so the sequence is short enough to fit Moshi’s 12.5 Hz frame budget, then projected through a single trainable linear layer.
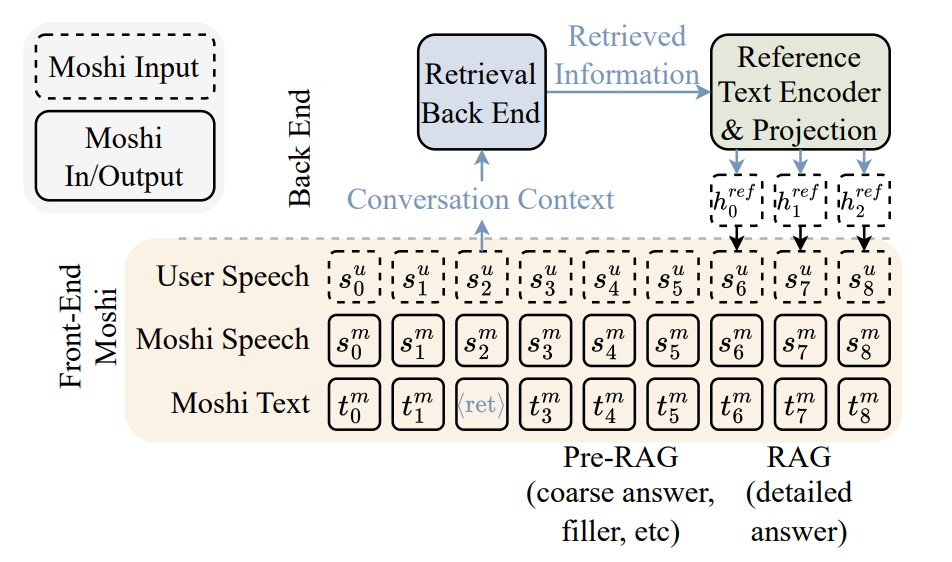
Those projected embeddings are then additively summed into Moshi’s input vector at the temporal Transformer level, over a short window. Mathematically, the input that was originally:
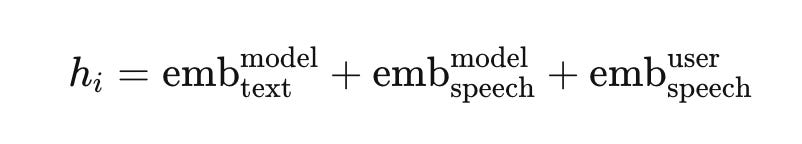
becomes:
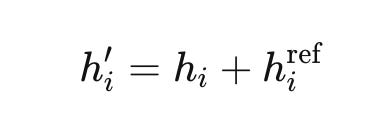
for the duration of the reference’s compressed embedding sequence, and reverts to plain hi afterwards. The reference is a transient side-channel that biases Moshi toward grounded facts during the body of its turn — nothing more, nothing less.
The authors did try “insertive” injection (treating the reference as extra tokens spliced into the input sequence) and found it scored higher on accuracy. They rejected it anyway, because lengthening Moshi’s input sequence hurts the model’s ability to hold long conversations. Additive injection was the better engineering trade-off.
What changed in Moshi to make Moshi-RAG work
The architecture changes are surprisingly minimal from orginal Moshi. The paper says it outright: “the only modifications from the original Moshi model are the introduction of a special retrieval trigger token <ret> and a reference text encoder.” In practice there are four small additions:
A new
<ret>token in the text vocabulary, placed in training data immediately before the “lead” portion of every knowledge-intensive turn (using TTS forced alignment).A frozen ARC-Encoder that compresses retrieved text 4× into Moshi’s embedding space.
A one-layer trainable linear projection sitting between ARC-Encoder and Moshi.
A learnable
h_dropoutvector that replaces the reference 20% of training time, so Moshi learns to behave gracefully when retrieval fails or is late.
The base Moshi backbone — the RQ-Transformer, Mimi codec, dual-channel design — is untouched. MoshiRAG is fine-tuned from the original Moshi checkpoint with 100k updates at a tiny 2 × 10⁻⁶ learning rate.
4. Thinking Machines’ Interaction Model
The TML blog post is up-front about the lineage: “This approach builds upon prior work like Qwen-omni, KAME, MoshiRAG.” But the scale and the design choices have moved on substantially. The demoes are incredible, to say the least. Here is on more example. You can see more in the blog.
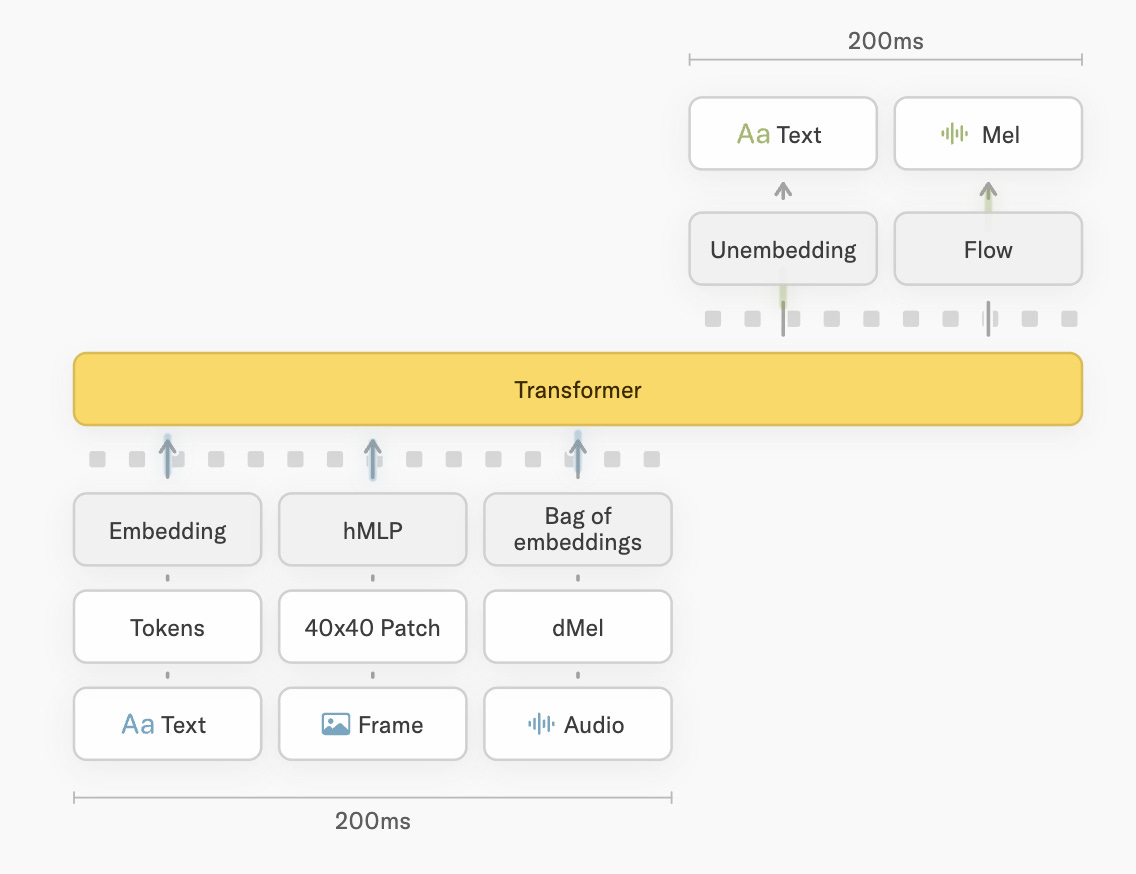
Time-aligned micro-turns. Where Moshi works at 12.5 Hz (80ms frames), TML works in 200ms chunks. Each chunk interleaves input and output across all modalities — audio, video, and text. There are no turn boundaries, no VAD, no harness. We will talk more about it in the next section.
Encoder-free early fusion. On the input side to Interactive Model, the blog has following details: Audio enters as dMel features through a light embedding layer. Video enters as 40×40 patches through a small hMLP. Audio output uses a flow head rather than a discrete codec. All of it is co-trained from scratch with the transformer. The 12B active parameters deal with all the modalities.
The background model split. This is the part that most directly echoes MoshiRAG. The interaction model handles real-time presence. When a task needs deeper reasoning, planning, or tool use, the interaction model delegates to a background model that runs asynchronously, then weaves results back into the conversation as they arrive — at a moment “appropriate to what the user is currently doing, rather than as an abrupt context switch.” That last phrase is exactly the MoshiRAG philosophy: hide the retrieval latency inside the natural rhythm of speech. One call out: where MoshiRAG bolts on a separate Whisper-class streaming ASR (1B parameters, frozen), TML does not explain whether they use an ASR model or not to provide input to the background model, but it is quite likely they do.
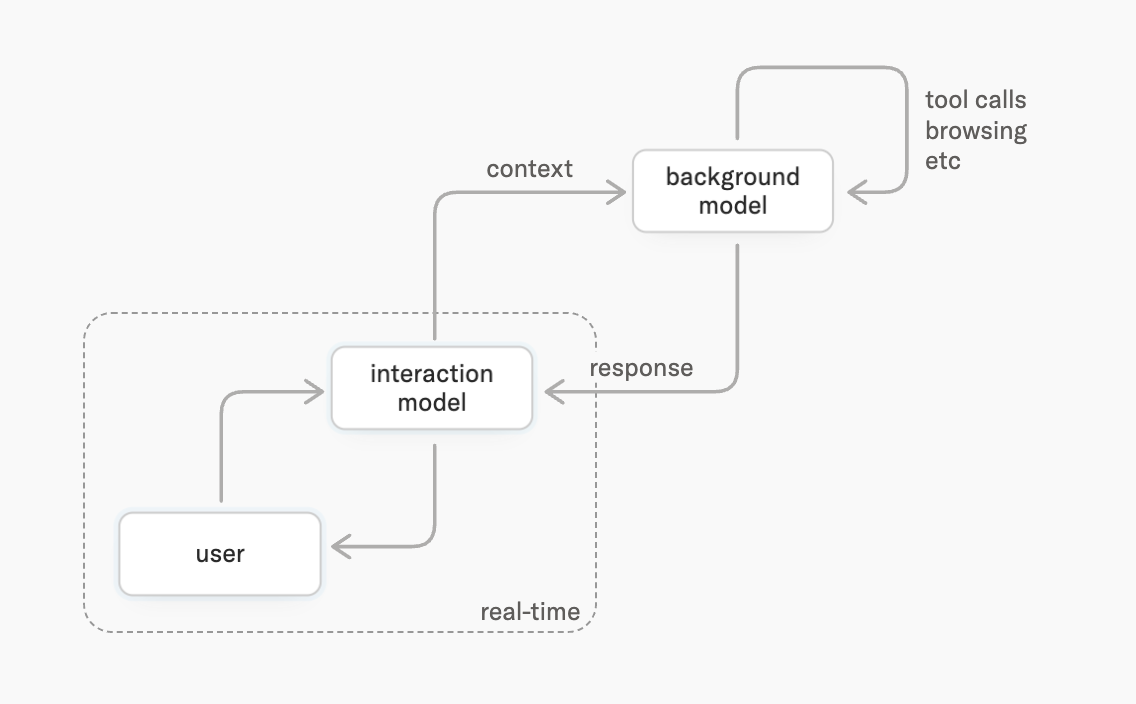
What the Thinking Machines blog does not tell us is how results come back into the interaction stream. MoshiRAG’s answer — additive embedding injection at the temporal Transformer level — is documented in the paper. TML’s mechanism is not. But the surface-level analogy is striking enough that it is reasonable to guess the implementation belongs to the same family.
Thinking Machine’s approach to model input:
Here there is a difference from Moshi
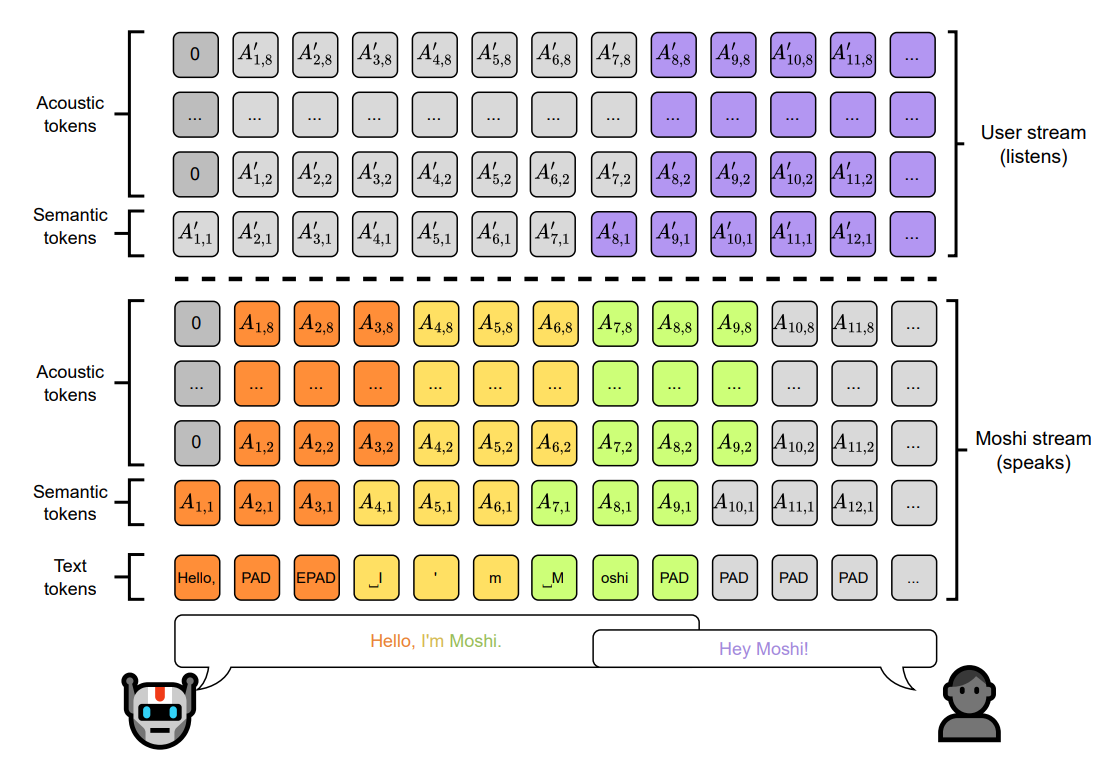
Moshi: combined at every frame. As we discussed earlier, Moshi’s temporal Transformer receives, at each 12.5 Hz time step, one input vector that is the element-wise sum of three streams: model text, model speech, and user speech embeddings (Equation 1 in the paper). MoshiRAG adds a fourth optional term for the reference embedding during the injection window. There is no notion of “input now, output later” within a frame. At every 80 ms tick the model simultaneously sees the user’s incoming audio and predicts its own next text and audio tokens. Three concurrent streams collapse into one combined vector per step.
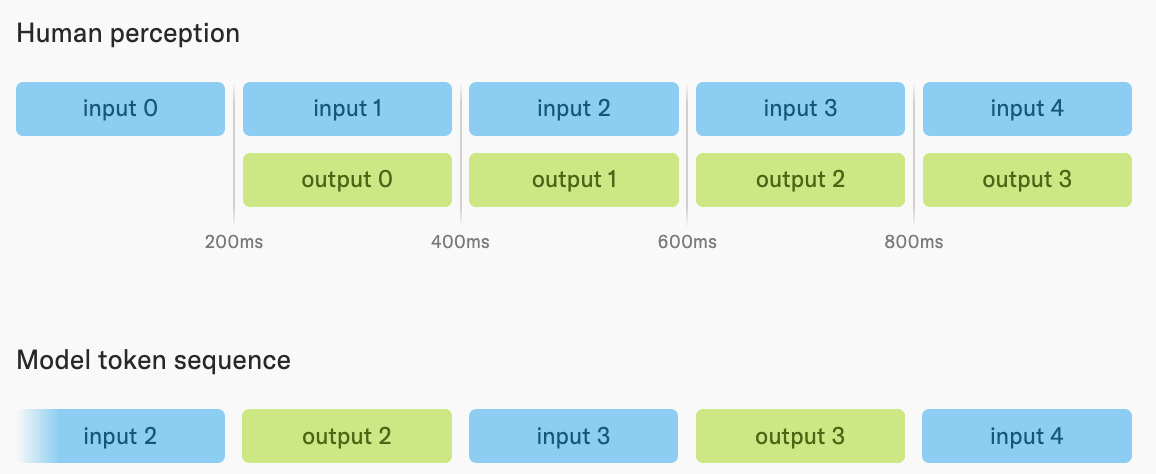
TML Interaction Model: interleaved at chunk granularity, combined within a chunk: Thinking Machines runs at 200 ms chunks (5 Hz). The blog illustration is explicit about the macro structure — “the model receives a single interleaved token sequence” — and shows it as input_0 → output_0 → input_1 → output_1 → input_2 → output_2 → …. So at the between-chunk level, the model alternates: it consumes 200 ms of input, then emits 200 ms of output, then consumes the next 200 ms of input, and so on. That is sequence-based, not parallel.
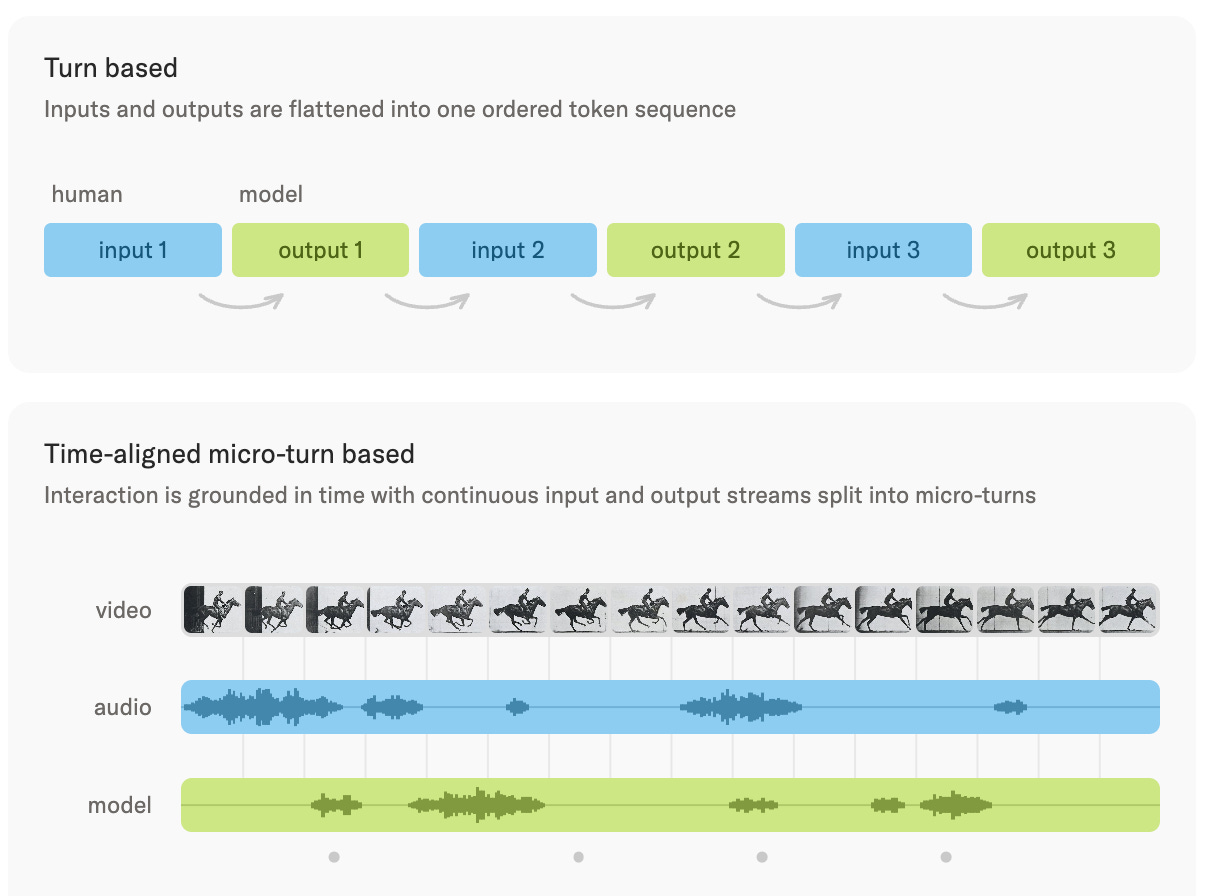
But within a single 200 ms chunk, multiple modalities are still combined, just in a different way. The architecture diagram in the blog shows text frames, audio dMel features, and 40×40 video patches (encoded via hMLP) all flowing into model input after bring embedded.
Size comparison

TML Interaction Model’s Inference optimisations
The blog is pretty brief on this. Here is my read: the 200ms micro-turn design fundamentally changes what inference looks like. Standard LLM serving is optimised for big prefills followed by long decodes; TML produces a continuous stream of tiny prefill+decode rounds, five per second per active session. Per-turn overhead dominates the math, so most of the optimisation work is about killing that overhead.
Streaming sessions. Instead of treating each 200ms chunk as a fresh request that re-allocates buffers and rebuilds metadata, the inference server keeps a persistent sequence in GPU memory and appends incoming chunks to it. A version of this is upstreamed to SGLang.
Custom MoE kernels. TML-Interaction-Small is a 276B MoE with only 12B active. At interaction time the per-step batch is tiny, so the standard grouped-GEMM kernel that MoE inference usually relies on wastes most of its throughput. Thinking Machines replaced it with a GATHER+GEMV strategy — gather small per-token activations to the right experts, then run GEMV rather than GEMM — drawing on similar work in PyTorch’s gpt-fast and Cursor’s “warp decode.”
Latency-tuned kernel shapes. Beyond MoE, the kernels are explicitly tuned for the unusual shapes of bidirectional serving — where prefill and decode happen continuously at small sizes rather than in the canonical “big prefill, long decode” pattern.
The post is notably quiet on quantisation, speculative decoding, and KV-cache compression.
TML Background Model’s Inference optimisations & Hybrid Architecture
While the blog does not state what background model TML team used, it is probably a state of the art model. If you try to use an off the shelf LLM API like Sonnet 4.6 or Opus 4.7 you typically get 50-100 tokens per second per user. However, that is not enough for generating tool calls, executing them, preparing a response and handing it back to the interaction model. In such scenarios Cerebras like performance can make a material difference to serve SOTA intelligence in the real time. Cerebras can serve 1500+ tokens per second for SOTA open source models.

Furthermore, one could deploy a hybrid architecture wherein interaction model runs on an edge server or on a server in a datacenter, and it connects to the background model over a fast network (within the same location or over the internet). Even if the connection to the background model is lost, the system will continue to work as interaction model has enough intelligence to carry on a conversation. The TML blog is not 100% clear on how the models interact. If it is text out, text in, it is easy. But if there is tighter integration involving activations, then it may require higher bandwidth (though I don’t think this is what is happening. It is most likely text out, text in). Also, for now Cerebras does not have built in web search from what I know, so there will need to be an intermediate agent - which would also need to be fast.
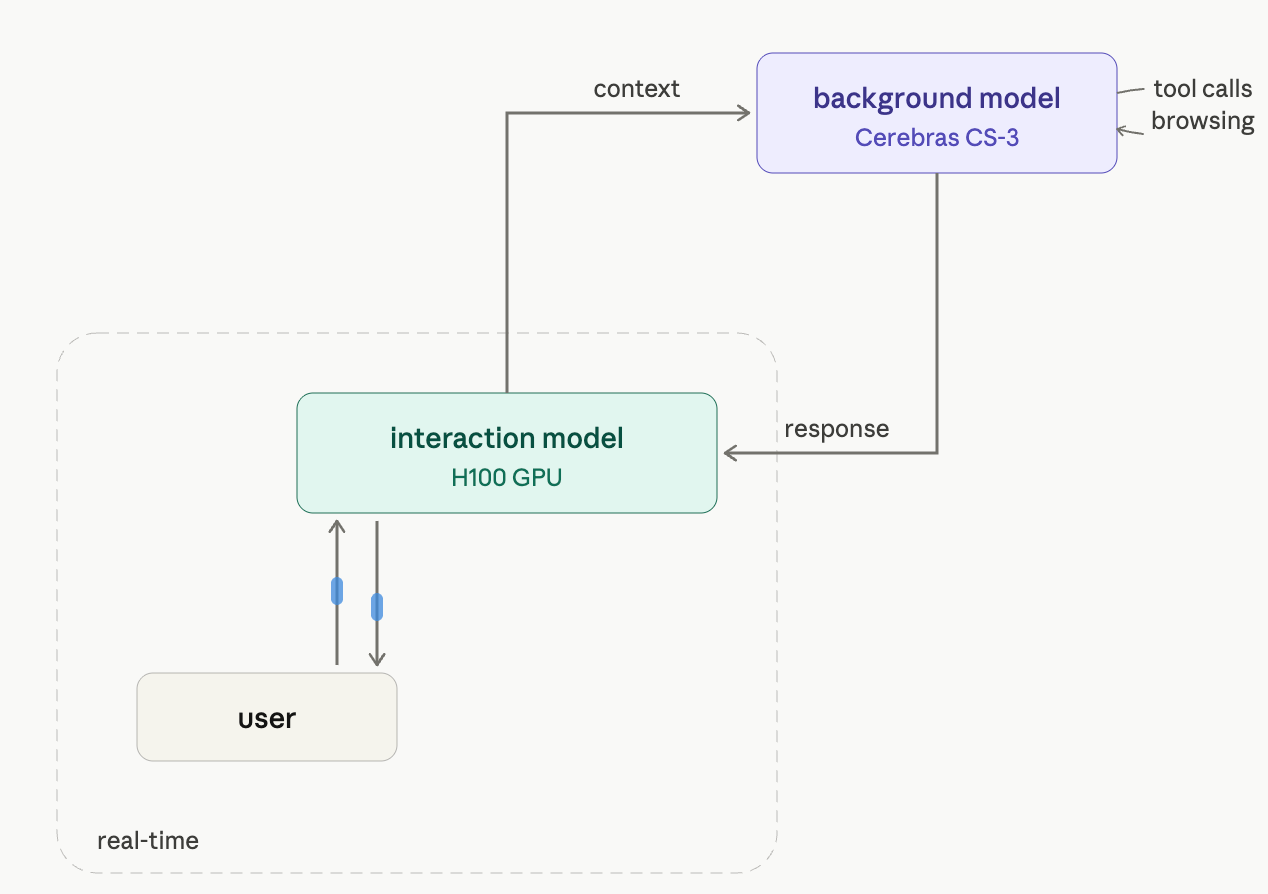
Ambient AI
This is a privacy preserving setup and may be desired by many as interaction model is exposed to voice and video - which may haev sensitive content. This approach can safely enable “Ambient AI”. Ambient AI, often referred to as ambient intelligence (AmI) or ambient computing, represents a shift in artificial intelligence from reactive (waiting for prompts) to proactive and invisible (acting on context).
In my mental model if coding is 1X of token use, AI co-working is going to be 10X of token use, and Ambient AI is going to be 100X of token use. This two model architecture pattern and chipset like Cerebras are vital to enable it.
Trivia
One of my favourite blogger Stratecherry believes Cerebras main use case is not Coding, but such real time interaction use cases in voice (Ambient AI) and possibly robotics domain. I believe Cerebras - in addition to such performance sensitive applications - is also very important for coding, as well as, personal AI agents use cases when users are in driving seats. Stratcherry believe background agents will replace all the coding and personal agent use cases. I believe, users will want to be in the loop forever, not because they have to, but because they want to - just like people want to browse their social media themselves. It is immensely satisfying - plus it can compound the output! But, that is a debate for another time…
You can also read this excellent deep dive on Cerebras by Semianalysis.
Kyutai, take a bow!

Image Source: Techcrunch
Kyutai was launched in November 2023 at Station F in Paris, a non-profit AI lab seeded with roughly €300 million from Xavier Niel (Iliad), Rodolphe Saadé (CMA CGM), and Eric Schmidt's foundation, with a mandate that is still rare in the field: do frontier research, publish everything, release the weights, and treat open science as the default rather than a marketing posture. Six scientists took the stage that morning, and their CVs read like a quiet history of European generative AI.
Patrick Pérez, who became CEO, had spent decades at Inria, Microsoft Research, Technicolor, and Valeo, where he ran the valeo.ai lab.
Hervé Jégou had helped found Meta's FAIR Paris office and is the mind behind product quantization and the FAISS vector-search library that quietly underpins much of modern retrieval.
Edouard Grave came from FAIR's language modelling group.
Laurent Mazaré arrived from DeepMind by way of Jane Street.
Neil Zeghidour and Alexandre Défossez, both veterans of Google Brain, DeepMind, and Meta, had between them already invented many of the neural audio codecs the field now takes for granted — SoundStream, EnCodec, MusicGen, AudioLM.
When this team turned its attention to full-duplex speech, the result was Moshi: a system that did not just compete with the cascaded pipelines of the day but made them look like a category error. MoshiRAG followed in 2026, extending the same architecture with asynchronous retrieval while keeping the open-science commitment intact — every detail down to the training-time retrieval-delay sampling distribution is in the paper. In late 2025, Zeghidour, Mazaré, and Défossez spun out Gradium to commercialise the voice work while keeping the lab close, a quietly elegant solution to the hard economic question of how a non-profit funds frontier compute.
While Thinking Machine should get massive well deserved credit for bringing us this far, Moshi paved the way for this revolution. The lineage matters. So does the lab that chose to publish it. Many thanks to the team behind Kyutai!!!
Closing thoughts
Moshi proved you could ditch the cascaded ASR–LLM–TTS pipeline and get a real full-duplex speech model. MoshiRAG proved you could keep that real-time front end and still get factuality by farming knowledge work out asynchronously.
Thinking Machines is now proving you can scale the same two-tier idea to a 276B/12B Active MoE backbone, add video, and still hit sub-second turn-taking latency and basically build your HER. You could add more capable agents between the interaction model and the background model and create phenomenal applications that will feel much more pleasant to interact with. This will also create a market for Cerebras style inference accelerators. And it is a big market.
TML’s interaction model is incredibly impressive, and as they say: “this is the worst it will ever be”!
Also, if you haven’t watched the movie Her, let me tempt you by showing this trailer.